
In the age of data-driven technologies, our machines and algorithms learn continuously from vast amounts of data. But what if we want them to “unlearn” specific information? Machine unlearning (MU) is the study and practice of ensuring that models can efficiently and effectively forget specific training data, especially in light of growing privacy concerns. A simple analogy to understand MU is like imagine you have a cookbook with several recipes. Over time, you add more recipes to it. Now, suppose you want to remove a particular recipe. Instead of rewriting the entire cookbook without that recipe, you’d preferably just erase or remove that specific page. Similarly, MU tries to efficiently “erase” specific data without having to “rewrite” the entire machine learning (ML) model.
The need to unlearn
As various organizations hold a multitude of user data, there arises a compelling need to manage and control the privacy of this data, especially when entwined with ML models [1]. ML models ingest vast amounts of data, so they inadvertently store or “memorize” patterns. This not only poses a threat to individual privacy but also places organizations in a precarious position when complying with global legislations, such as the General Data Protection Regulation (GDPR) and its “Right to be forgotten” clause [2]. Thus, to unlearn these patterns (or making the AI system intentionally forget a trained data) is a cumbersome task for organizations and require investment of significant cost to retrain models.
The shift towards Machine Unlearning
Recently, a new emerging paradigm, MU has gained traction within the AI research community [3]. MU focuses on the deliberate and systematic removal of specific data patterns from trained machine learning models, ensuring they no longer retain any trace or influence from the deleted data [4]. This is pivotal, not only for the preservation of user privacy, but also for maintaining the adaptability and relevance of ML models. The challenge, however, lies in efficiently erasing such data imprints without the need to retrain models entirely, which is computationally expensive and time-consuming. Thus, advanced techniques in MU are actively being explored to strike a balance between computational efficiency, model performance, and data privacy [5].
A formal definition of Machine Unlearning
Figure 1 presents a formal overview of MU. We consider there are k users, where personal and sensitive attributes like Name, Age, Gender, Location, User Identification Number (SSN), and his Web preferences are stored by any company (or social media platforms). Each user Ui data has a statistical importance Si in data distribution, which is stored in D. A ML model M trains on D, to give predictions P on the data (which are used for companies) to suggest or recommend users for specific products. However, any kth user Sk sends a data removal request to the data D. The removal D’ = D – {DSk} is fed to a MU model M’. An ideal MU algorithm should produce a statistical distribution of models identical to what would be obtained by retraining D’ on M. This stringent definition aligns in close coherence with objectives of privacy. Thus, without retraining, the prediction P’ obtained from the MU model (without Sk) data should be as close to P, as with the inclusion of Sk data.
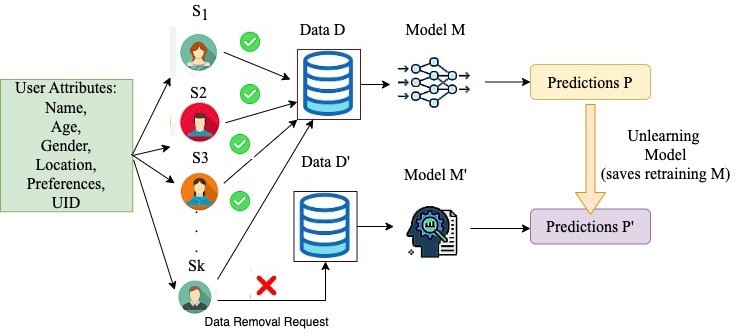
Figure 1: A Formal View of Machine Unlearning
Concepts and Techniques
- Sharding: This involves breaking down the vast dataset into smaller, manageable chunks, akin to dividing a large book into smaller Each chunk (or shard) is used to train a separate, smaller model. When a data point needs to be unlearned, only the relevant “volume” is addressed, avoiding the need to revisit the entire “book.”
- Slicing: Within each shard, the data is further divided into slices, like chapters in a book. The model is incrementally trained using these slices. By saving checkpoints at each stage, we can revert to a specific “chapter” when unlearning is required, instead of starting the entire volume
- Aggregation: With multiple models (from sharding), we need a mechanism to consolidate their This is similar to referencing multiple volumes of an encyclopedia. A majority voting strategy is often employed, where each model’s output is considered a vote, and the final decision is based on the most common output.
A trade-off between accuracy and performance?
While techniques like sharding and slicing expedite the unlearning process, they come with challenges:
Accuracy Degradation: Smaller models might not be as accurate as one large model. It’s like having multiple pocket-sized guides instead of one comprehensive encyclopedia. There’s a trade-off between speed and
Storage Overheads: Slicing demands additional storage due to the multiple checkpoints, akin to saving drafts of different chapters
Conclusion
Machine unlearning is like teaching our digital tools the art of forgetting, and it’s becoming an increasingly important chapter in the world of privacy-focused machine learning. As we continue to feed these machines with heaps of data, it’s clear that we also need to equip them with an “erase” button. Current methods like sharding and slicing are our initial steps towards this, but they come with their own set of quirks and hiccups. On one hand, they give us a blueprint to break data down, making the forgetting process a bit easier. On the other hand, we’re faced with potential accuracy hiccups and the challenge of managing more data storage. And let’s not forget about the ever-present challenge: ensuring that as these machines “forget”, they truly leave no trace behind. As we look forward, we need to refine our current strategies and keep our eyes peeled for new challenges that will undoubtedly crop up in this dynamic and evolving field. The road ahead is long, but the pursuit of balancing efficiency with privacy is well worth the journey.
References
- Xu, , Zhu, T., Zhang, L., Zhou, W., & Yu, P. S. (2023). Machine unlearning: A survey. ACM Computing Surveys, 56(1), 1-36.
- Kaur, G., & Bharti, A. (2022). Right to Be Forgotten in a Post-AI World: How Effective is This Right Where Machines Do not Forget?. In Emerging Technologies in Data Mining and Information Security: Proceedings of IEMIS 2022, Volume 2 (pp. 59-62). Singapore: Springer Nature
- Schimke, (2022). Forgetting as a social concept. Contextualizing the right to be forgotten. In Personality and Data Protection Rights on the Internet: Brazilian and German Approaches (pp. 179- 211). Cham: Springer International Publishing.
- Liu, J., Xue, M., Lou, J., Zhang, X., Xiong, L., & Qin, Z. (2023). MUter: Machine Unlearning on Adversarially Trained In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 4892-4902).
- Zhang, , Lu, Z., Zhang, F., Wang, H., & Li, S. (2023). Machine Unlearning by Reversing the Continual Learning. Applied Sciences, 13(16), 9341.
About the module authors-
Dr. Pronaya Bhattacharya is an esteemed academician and researcher currently serving as an Associate Professor at Amity School of Engineering and Technology, Amity University, Kolkata, India. With a strong educational background, he earned his Ph.D. in Optical Communications from Dr. A. P. J. Abdul Kalam Technical University in 2021, following an M.Tech in Network Security and a B.Tech in Computer Science and Engineering. Dr. Bhattacharya is widely recognized for his prolific research contributions, having authored over 150 research papers published in leading SCI journals and prestigious IEEE COMSOC A* conferences. His work spans diverse areas such as healthcare analytics, optical switching and networking, federated learning, blockchain, and the Internet of Things (IoT). His publications have appeared in renowned journals including IEEE Journal of Biomedical and Health Informatics, IEEE Transactions on Vehicular Technology, and IEEE Internet of Things Journal, among others. He holds an impressive H-index of 31 and an i10-index of 71, with over 3354 citations to his credit. Additionally, Dr. Bhattacharya has 8 granted/published patents and serves on the editorial boards of esteemed publishers such as Elsevier, Springer, and Wiley. His expertise is further acknowledged through his role as a keynote speaker, technical committee member, and session chair at various international conferences. He is also currently serving as a fellow member of Threws community.
Dr. Pushan Kumar Dutta holds a PhD from Jadavpur University and completed a postdoctorate with a scholarship from the Erasmus Mundus Association at the University of Oradea, Romania. His research interests span a wide spectrum, including data mining, AI, edge computing, predictive analytics, and Earthquake Precursor Study. As an accomplished editor and author, Dr. Dutta has contributed significantly to the academic community, editing multiple books for reputable publishers and publishing numerous book chapters and articles in esteemed journals. Dr. Dutta’s expertise is recognized globally, evidenced by his keynote speeches at international events like the Data Science Europe summit. His contributions to academia include over 42 articles published in Scopus indexed journals and several IEEE Xplore articles and Springer Lecture Notes publications in 2023 alone. Beyond academia, Dr. Dutta is actively involved in mentoring students and coordinating sports and innovation competitions at Amity University Kolkata. He teaches classes on IoT, robotics, and engineering and serves on various technical programming committees for prestigious conferences worldwide.